You Might Want To Block OpenAI's New GPTBot - Here's Why

AI chatbots like Google's Bard and OpenAI's wildly popular ChatGPT are trained using massive amount of data scraped from the internet. As expected, every AI lab is racing to make their chatbots smarter using all the data that they can get their hands on — a tactic that has proven quite controversial because they don't often pay the creator or owner of the scraped content. For example, OpenAI recently launched GPTBot, a web crawler that sifts through information it comes across on the internet.
"Web pages crawled with the GPTBot user agent may potentially be used to improve future models," OpenAI explains on its website. The Microsoft-backed company, however, clarifies that the AI bot won't scrape content from websites that serve paywalled content. Moreover, it won't glean any content that is deemed personally identifiable, or contains content that violates its own safety guidelines and policies.
Now, GPTBot is not the only internet crawler out there. Stable Diffusion and LAION use Common Crawl, a non-profit which owns petabytes worth of internet data, dating back to 2008. If you seek to disable GPTBot, you might as well take the initiative to block the Common Crawl's CCBot web scraper. Just for the sake of information, Google also used the Common Crawl dataset to train Bard, its very own ChatGPT rival.
How to disable OpenAI's GPTBot?

Preventing OpenAI's web crawler from accessing the contents of a website is a fairly simple process. All it needs is a slight tweak to the "robots.txt" field, which essentially tells a search engine what areas of a website it can access, and those it can't. In technical terms, it is a "crawl directive" — and since GPTBot is a web crawler, it falls under the domain.
A robots.txt file is essentially a plain text document that lives in a website's root directory, and tampering with it can lead to serious harm. If you own a website, but don't know your way around code or backend systems, you should ideally ask an expert to do it on your behalf.
That's because robots.txt — short for Robots Exclusion Protocol — plays a crucial role in developing and indexing your website's content by all major search engines. These code snippets not only manage the level of content access to your website, but also limit the extent of indexing and control the crawling rate.
Yoast, a popular SEO plugin for WordPress-based websites, allows users to edit robots.txt files easily. You can also edit it from your website's SEO dashboard by accessing the "Robots.txt Editor" from the settings section. Once there, you have to enter the "Disallow" command for the user agent called "GPTBot." The exact code is as follows:
User-agent: GPTBot
Disallow: /
Why AI bots need to scrape the web?

When a ChatGPT user enters a prompt that would entail up to date information, OpenAI's chatbot would tell you that its training data only dates as far back as 2021. OpenAI's chatbot loses out for two reasons. First, it doesn't want to comment on current affairs, especially when they are unfolding in real-time, to avoid giving misleading or biased answers.
Secondly, fresh information often comes from direct sources. Given its penchant for skipping citations, it could very well land OpenAI into some copyright violations. However, that isn't dissuading AI labs from trying.
OpenAI recently inked a deal with AP News, allowing the AI lab to learn from AP's extensive archive of news content for training. However, the AP deal is an outlier: Publishers across the world are apprehensive of similar deals because of the extensive scraping done in the not-too-distant past, where data from media outlets was used without proper permission or disclosure to train AI models. Getty even filed a lawsuit against Stability AI over similar concerns.
Now, the stakes are higher. GPT-powered bots are indiscriminately scraping from the work of authors. Comedian and actress Sarah Silverman recently sued OpenAI for picking up content from her book without consent for training its AI language model. Similar lawsuits are brewing in the digital arts industry, with artists alleging that AI labs used their artwork to train generative AI models such as OpenAI's Dall-E and Stable Diffusion.
What's the incentive to block GPTBot?
Allowing GPTBot to access your site can help AI models become more accurate and improve their general capabilities and safety," says OpenAI. That proclamation plays straight into OpenAI's benefit, because ChatGPT is getting better, but it won't be extending any benefit to owners of websites that it scraped data from.
When AI chatbots glean content from a website, it adds knowledge to its pool, and then regurgitate the information it scraped from a website that had the relevant answers. Chatbots do so without mentioning the source.
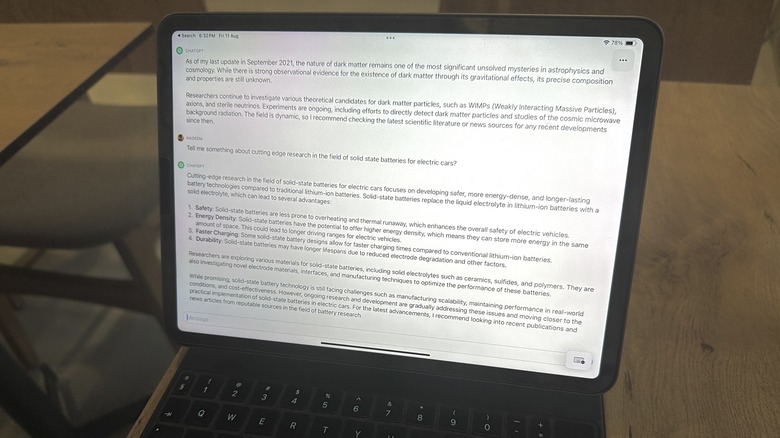
Google's Bard AI chatbot only started showing citations in May 2023, following in the footsteps of Microsoft's Bing Chat. ChatGPT still won't give you citations. Take for example the question (pictured above) I asked ChatGPT about recent research innovation in the field of solid state batteries for electric cars.
It gave multiple examples, but didn't provide a single source for the academic journal — paywalled or free — and the publications that published stories about that particular research. In fact — as this Indiana University experiment found — ChatGPT can omit or misquote citations even if it is provided plenty of information in the prompt.
The core problem here is that once users get their answers from ChatGPT, they won't find it necessary to perform a regular Google search, visit a few websites, and find answers on their own. When that doesn't happen, publishers lose the crucial web traffic that keeps them alive, not to mention if ChatGPT gets it wrong.
Should you worry about GPTBot?

OpenAI used datasets from Common Crawl (60%), WebText2 (22%), Books1 (8%), Books2 (8%), and Wikipedia (3%) to train the underlying model behind ChatGPT. Microsoft's Bing Chat — which is also built atop GPT foundations — also relies on the same scraped information. Google Bard is not too dissimilar.
The company's privacy policy says it may "use publicly available information to help train Google's AI models and build products and features like Google Translate, Bard, and Cloud AI capabilities." In fact, Google is of the opinion that AI systems should be allowed to freely scrape information unless the publisher opts out of it.
Interestingly, Google is vouching for the creation of an industry standard — similar to the robots.txt technique described above — that would allow AI labs to "responsibly" use publicly-available information to train AI models. Those plans have yet to materialize.
While Google's intentions seem noble, the company's track record itself is chequered. The U.K.'s DailyMail is suing Google for using its news article to train AI models, reports The Telegraph. A bunch of other publishers are also up in arms against Google and Microsoft.
As regulators scramble to come up with appropriate guardrails to stop AI labs from having a free lunch with publisher's valuable data, the likes of Reddit and Twitter have choked their API pipelines to avoid scraping. But so far, nothing consequential has happened. Until then, blocking scrapers seems like the only reliable respite for publishers.