Meta's Latest AI Research Tool Creates Music From Text Prompts

Meta has just released a new generative AI tool focused on audio that can generate musical tunes based on text prompts, just the way OpenAI's Dall-E can conjure images. Named AudioCraft, Meta's image generation AI tool consists of three distinct models — MusicGen, AudioGen, and EnCodec — all of which have been pushed into the open-source domain. These models were trained on a catalog of licensed music and publicly-available sound effects, and promise high-quality music generation with minimal audio artifacts.
Using text prompts, these models can help generate a wide range of sounds such as birds chirping, moving cards, and more. Meta says one day, the tool can even be used to create epic music as you recite bedtime stories to kids. Staying close to its social media roots, Meta hopes AudioCraft can be of great help not just for businesses, but also content creators that want to add some unique sonic pizzazz to their videos shared on platforms such as Instagram.
Another notable aspect that Meta touts is simplicity, claiming that its audio-specific AI engine is easier to use than rival platforms out there. This won't be Meta's first effort in the field of generative AI. The company also offers Voicebox, which is capable of generating audio clips in six languages while also denoising and stylizing them at the same time. Then there's CM3leon, a generative AI model focused on images and text.
Meta wants the world to improve AudioCraft
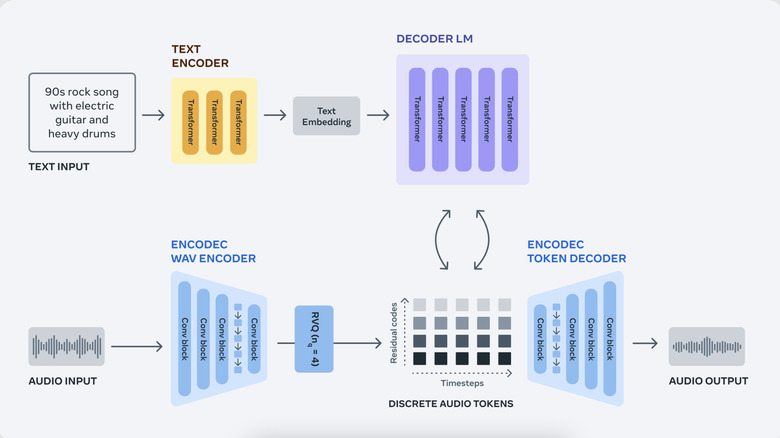
Audiocraft relies on what Meta calls "EnCodec Neural Audio Codec," which processes audio in the same tokenized format as your regular AI chatbots like ChatGPT or Bard. From the samples shared by Meta so far, it seems you can dictate the type of tones you want and the voice sources — which can be a musical instrumental or any other object ranging from a bird to a bus — to generate a sound clip using a text prompt.
Here's a sample of a text prompt: "Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves." It produces a 30-second clip, which actually doesn't sound half-bad, as you can listen to here in Meta's blog post. As convenient as it sounds, you won't have much granular control over generating your sound clips as you would have with a real instrument in your hands or a professional synth.
MusicGen, which Meta claims was "specifically tailored for music generation," was trained using approximately 400,000 recordings and metadata worth 20,000 hours of music. But once again, the diversity of the training data is a problem and Meta recognizes that, too. The training dataset is predominantly Western-style music with corresponding audio-text data fed in the English language. To put it simply, you will have better luck generating a country music-inspired tune instead of a folk Persian melody. One of the key objectives behind pushing the project into the open-source world is to work on the diversity aspect, it seems.