Meta's New Voicebox AI Serves Up Generative Text-To-Speech
Meta has introduced its own generative AI model, but instead of creating images like Dall-E or writing answers like ChatGPT, this one focuses on audio generation. Named "Voicebox," Meta's AI tool can instantly generate human-like audio clips. Then, it goes a step ahead and offers capabilities like noise removal and language translation in six dialects.
One of the most impressive abilities of Voicebox is clearing noise from an audio clip. For example, if an audio clip in which a person can be heard speaking is polluted by a car horn, the AI model removes the noise and returns almost crystal-clear audio. It's almost like Google's Magic Eraser tool, which removes unwanted objects from a photo, and then performs intelligent pixel-filling so that the removed elements blend seamlessly with the surroundings.
Voicebox can also perform multi-language speech sampling, and currently offers support for English, French, German, Spanish, Polish, and Portuguese. Thanks to its linguistic chops, Voicebox can return an audio clip in the preferred language, even if the text input is in another language. This could come in handy for conversations where language barriers exist.
Google already offers this convenience right in your ears if you own one of the recent Pixel Buds TWS earbuds and a Pixel phone. Meta has done remarkable work in this field too, thanks to its own Massively Multilingual Speech AI research models that can understand over 4,000 spoken languages from all over the world.
With great power comes great responsibility
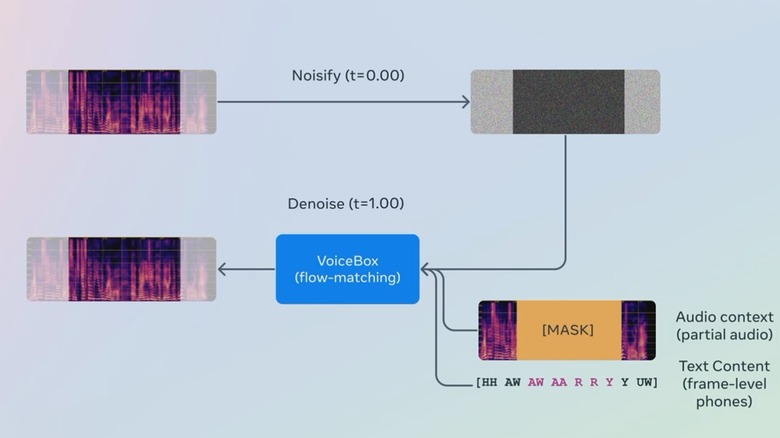
Voicebox relies on a novel training method called Flow Matching, which is claimed to offer higher intelligibility at text-to-speech jobs, and returns a higher rate of audio similarity when compared to the original training material. Compared to rival models out there, Meta says Voicebox brings the text-to-speech error rate down from 10.9% to 5.2%. It allows style transfer from one language to another, making the audio output sound more authentic.
But the most impressive capability in Voicebox's arsenal is the "zero-shot" learning approach, which means it doesn't need to be trained on a vast training data cache to do its job. All it needs is a two-second audio clip, and it will then learn everything from it, from the distinct tone and pitch to personal pauses — before it starts generating fresh audio clips with a similar sound profile.
For comparison, Microsoft's Vall-E AI model uses a three-second audio clip to train itself. Meta says its text-to-speech generation model is faster than Vall-E. Just like Microsoft, which paused the public release of Vall-E citing abuse risks, Meta is taking a similar approach with Voicebox.
"We recognize that this technology brings the potential for misuse and unintended harm," Meta argues, adding that it wants to take a responsible approach to AI innovation. The company has also released a research paper in which it has documented building a classifier model that can differentiate between Voicebox-generated audio and an authentic clip of a real human speaking.